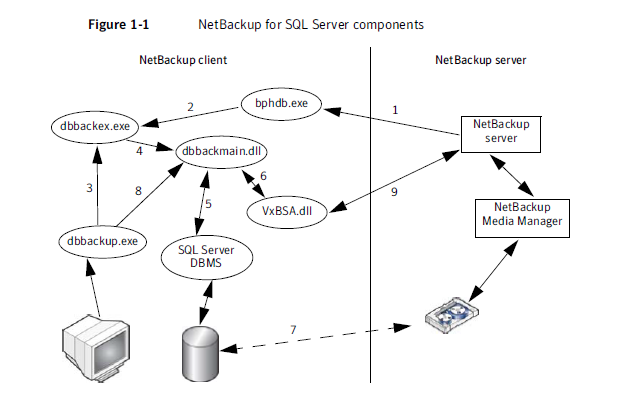
The Management Console Server (MCS) provides centralized administration (scheduling, monitoring, and management) for the Avamar server. The MCS also runs the server-side processes used by the Avamar Administrator graphical management console which is serviced by JAVA. When you start the Avamar GUI you are interacting with the MCS
PG28- EMC AVAMAR 6.1 ADMIN GUIDE
The MCS interacts with the client avagent to start backup and recovery. Avamar agents are platform-specific software processes that run on the client and communicate with the Management Console Server (MCS) and any plug-ins installed on
that client. The MCS contacts the client’s avagent process and starts an avtar to perform a backup or recovery.
I have made some changes on configurations on mcserver.xml files /usr/local/avamar/var/mc/server_data/prefs/mcserver.xml and after the changes i'll need to restart MCS to make sure it takes affect.
As usual, you will need to login as ADMIN, or in my case i login as root and then change to Admin ID
admin@utility-01:~/>:su - adminSTOP MCS (Its always suggested that you run dpnctl status first before stopping the MCS to check any services is down)
admin@utility-01:~/>:ssh-agent bash
admin@utility-01:~/>: ssh-add ~admin/.ssh/admin_key
admin@utility-01:~/>: dpnctl stop mcsAfter MCS Stopped, check the status
dpnctl: INFO: Shutting down MCS...
dpnctl: INFO: MCS shut down.
admin@utility-01:~/>: dpnctl status
dpnctl: INFO: gsan status: up
dpnctl: INFO: MCS status: down.
dpnctl: INFO: EMS status: up.
dpnctl: INFO: Backup scheduler status: down.
dpnctl: INFO: dtlt status: up.
dpnctl: INFO: Maintenance windows scheduler status: enabled.
dpnctl: INFO: [see log file "/usr/local/avamar/var/log/dpnctl.log"]
Start back MCS
admin@utility-01:~/>: dpnctl start mcsChecked again the status
dpnctl: INFO: Starting MCS...
dpnctl: INFO: To monitor progress, run in another window: tail -f /tmp/dpnctl-mcs-start-output-4109
dpnctl: INFO: MCS started.
admin@utility-01:~/>: dpnctl statusDuring the start back MCS , there's a line shows to tail one file to monitor the progress. Here is the files, it will show you verbose
dpnctl: INFO: gsan status: up
dpnctl: INFO: MCS status: up.
dpnctl: INFO: EMS status: up.
dpnctl: INFO: Backup scheduler status: down.
dpnctl: INFO: dtlt status: up.
dpnctl: INFO: Maintenance windows scheduler status: enabled.
root@utility-01:~/#: tail -f /tmp/dpnctl-mcs-start-output-4109Sometime, in older version of Avamar when you stopped MCS it will stop the maintanencice and schedule, to start it back run this command:
check.mcs passed
=== PASS === check.mcs PASSED OVERALL (prestart)
Starting Administrator Server at: Thu Oct 11 14:51:00 SGT 2012
Starting Administrator Server...
2012-10-11 14:51:22.988:INFO::Logging to STDERR via org.mortbay.log.StdErrLog
2012-10-11 14:51:23.065:INFO::jetty-6.1.23
2012-10-11 14:51:23.100:INFO::Extract lib/axis2.war to /usr/local/avamar/var/mc/server_tmp/Jetty_0_0_0_0_9443_axis2.war____.w8a9ms/webapp
2012-10-11 14:51:26.267:INFO::Started SslSocketConnector@0.0.0.0:9443
Administrator Server started.
INFO: Starting Data Domain SNMP Manager....
INFO: Connecting to MCS Server: utility-01.corpnet2.com at port: 7778...
INFO: Successfully connected to MCS Server: utility-01.corpnet2.com at port: 7778.
INFO: No trap listeners were started, Data Domain SNMP Manager didn't start.
dpnctl start maint
dpnctsl start sched